Da mit den neuen Top-Level-Domains von Google eigentlich eine Zweckentfremdung durch Phishing vorprogrammiert ist (bzw. auch schon eintritt) und wir uns gleichzeitig keinen nicht-verdächtigen Einsatzzweck o.g. Domains vorstellen können, haben wir uns entschieden, diese beiden Top Level Domains zu blocken.
So geht’s:
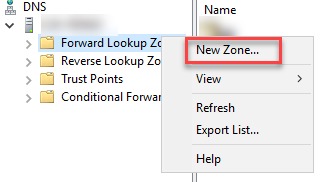
Im Windows DNS-Server (meistens der Domain Controller) legen wir eine neue Forward Lookup Zone (dt. irgendwas mit Vorwärts) an:
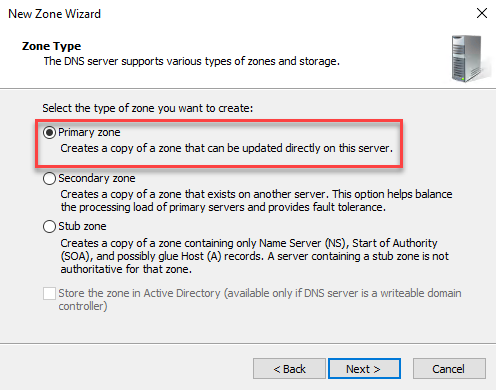
Wir wählen dann „Primary zone“ bzw. „Primäre Zone“ aus:
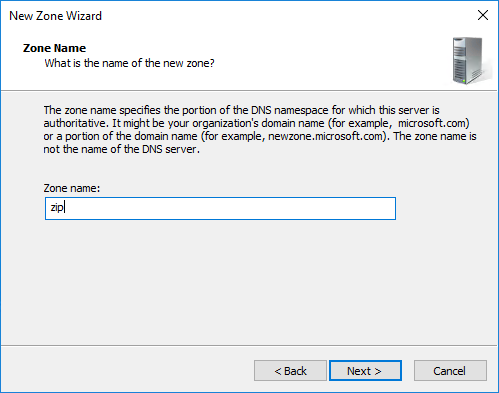
Als „Zone name“ bzw. „Zonennamen“ setzen wir dann die zu blockierende Domain ein, z.B. „zip“ – Ganz wichtig: Ohne Punkt oder sonst was:
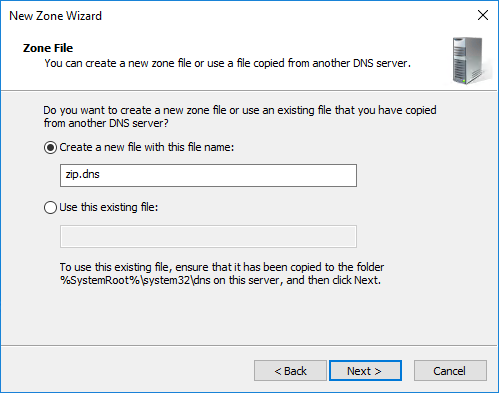
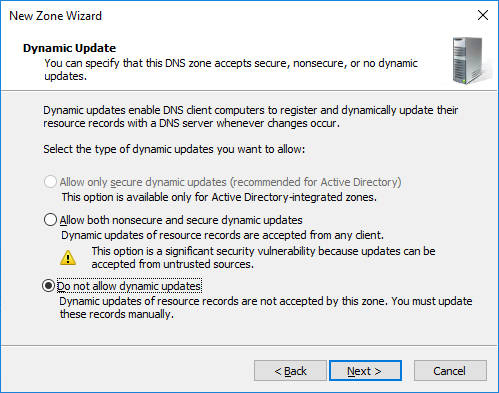
Die nächste Abfrage können wir so bestätigen:
Und auch die nächste Einstellung können wir so lassen:
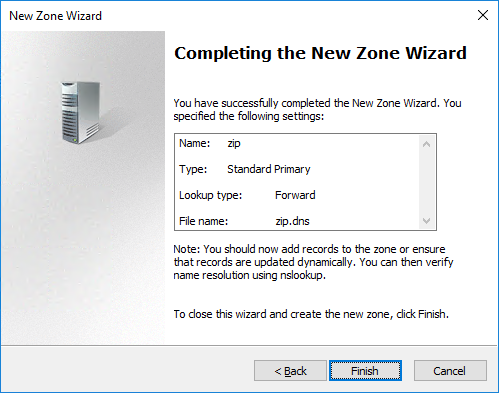
Abschließend bestätigen wir die Zusammenfassung mit Klick auf „Finish“:
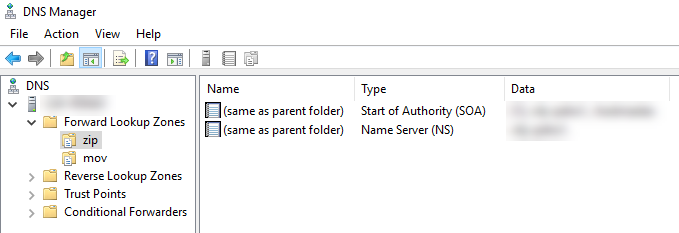
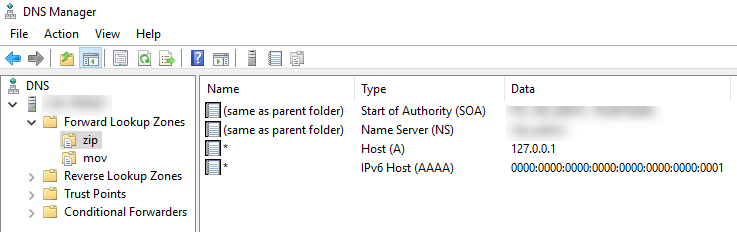
Wenn das abgeschlossen wurde, sehen wir links unter Forward Lookup Zones unter anderem folgende Zonen:
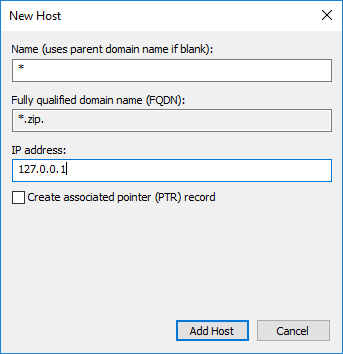
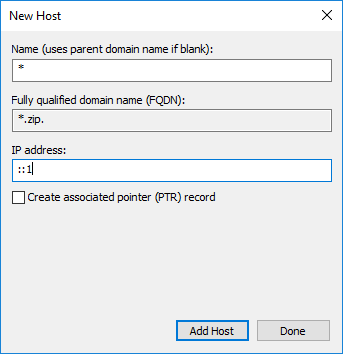
In jeder Zone legen wir nun einen A- und einen AAAA-Record an mit * als Host und localhost als Ziel:
… so dass es im Anschluss so aussieht:
Sobald das erledigt ist, wird jede Maschine, die diesen Server als DNS-Server verwendet, beim Auflösen des Namens nur die lokale IP bekommen und somit die eigene Maschine anfragen.
Man könnte natürlich noch einen Schritt weiter gehen und eine Landingpage bauen. Das wird aber spätestens beim HTTPS-Zugriff auf eine dieser Domains schwierig, da man hier dann auch noch über die CA ein Wildcard-Zertifikat bauen müsste.
Es wurde versucht, ein Laufwerk, welches per FC von einem All Flash-System präsentiert wurde, innerhalb von Windows zu formatieren. Dieser Vorgang dauerte horrend lange, wir stießen die Formatierung nachmittags an und konnten das Laufwerk erst am nächsten Vormittag weiterverwenden und in unseren Cluster importieren.
Eigentlich ein sehr unerwartetes Verhalten, erwartet man doch durch die Implementierung solcher Systeme vor allem einen Geschwindigkeitszuwachs.
Erklärung
Seit Windows Server 2012 ist die TRIM-Funktion in Windows standardmäßig aktiviert. Diese Funktion markiert gelöschte Sektoren auf einem Flashspeicher. Bei einer Formatierung eines logischen Volumes sorgt dies wohl für eine regelrechte Flutung des Mediums durch diese Unmap- und Trim-Kommandos.
Diese Funktion sollte also in dem Moment, wo Volumes von All Flash-Systemen dem Windows Server präsentiert werden, abgeschaltet werden.
Behebung
Man schaltet die Funktion ab, in dem über das Konsolenfenster (Win + R -> cmd) folgenden Befehl absetzt:
Hat man den Cache-Modus in Outlook für ein Exchange-Postfach auf einen bestimmten Zeitraum begrenzt, muss die Suche für frühere Ergebnisse auf dem Server fortgesetzt werden. Dazu wird man meist in der untersten Zeile der Suchergebnisse dann aufgefordert. Fälschlicherweise kann es dann hier zu der Meldung kommen, dass der Server offline oder nicht erreichbar ist.
Server unavailable. 12 months of results shown.
Fehlermeldung auf Englisch
Ob der Server tatsächlich ein Problem hat, können Sie bei Exchange-Postfächern sehr einfach über die „Outlook Web App“ prüfen. Wenn hier die Suche erfolgt, hat der Server normalerweise keine Probleme. Kommt es auch hier zu Fehlern, genügt es in den meisten Fällen, den Datenbank-Index neu aufzubauen. Das wollen wir aber in dem Fall nicht behandeln, wir gehen also davon aus, dass die Suche in OWA funktioniert.
Die Lösung, um die augenscheinliche Falschmeldung in Outlook zu beheben, ist mehr als seltsam. Bitte befolgen Sie folgende Schritte:
Klicken Sie per Rechtsklick links in der Ordnerübersicht auf Ihre Email-Adresse (also in der obersten Ebene)
Klicken Sie auf „Datendateieigenschaften….“
Klicken Sie auf „Ordnergröße…“
Wechseln Sie auf den Reiter „Serverdaten“. Hier müsste der Aufbau ein paar Sekunden benötigen.
Das war’s, sie können die Fenster wieder in umgekehrter Reihenfolge schließen.
Versuchen Sie im Anschluss die Suche erneut. Nun sollte die Schaltfläche wieder verfügbar sein, die es Ihnen ermöglicht, ältere Ergebnisse auf dem Server zu suchen.
Hat es Ihnen geholfen? Wir freuen uns auf Ihr Feedback!
Unter bestimmten Umständen ist möglich, dass das Outlook-Addin „Dynamics 365 for Outlook“ nach Installation und Einrichtung immer wieder einmal (oder spätestens bei Dynamics-Aktionen, wie dem Nachverfolgen von Mails) zunächst einen Internet Explorer-Tab mit dem Titel „Diese Website funktioniert in Microsoft Edge besser“ öffnet und anschließend den eigentlich innerhalb des Addins sichtbaren Inhalt in einem Edge-Browser öffnet.
Lösung
Vorausgesetzt, dass der Internet Explorer eh nicht mehr benötigt wird, können wir diesen einfach deinstallieren und das Problem somit umgehen. Wechseln Sie hierzu mit einem Administratorkonto in der Einstellungs-App zum Punkt „Apps & Features“ (einfach in der Suche eingeben) und klicken dann auf „Optionale Features“. Hier sollte der Internet Explorer 11 gelistet sein, den Sie markieren und dann mit Klick auf „Deinstallieren“ vom PC verbannen. Ein anschließender Neustart ist notwendig.
Wenn sich beim Öffnen mancher Windows 10-Apps und Anwendungen der Klang Ihres Systems verändert (in meinem Fall die Musik aus Spotify, die über ein Jabra-Headset abgespielt wird), so habe ich hier evtl. eine Lösung:
Das Jabra-Headset verändert die Soundqualität massiv beim Aufbau von Telefongesprächen. Während selbigen wirkt der Sound eher blechern und ohne große Höhen und Tiefen. Dieser Effekt trat bei mir auch beim Öffnen mancher Apps auf und ein kleines Mikrofon-Symbol in der Tray-Leiste führte mich zur Ursache des Problems: Auf dem Computer läuft unter anderem auch das Programm „Nvidia Geforce Experience“. Dieses interpretiert wiederum so manches Programm als „streambares Spiel“, vermutlich durch die GPU-Hardwarebeschleunigung – in meinem Fall u.a. PowerShell ISE, Windows 10 Kalenderapp, Kontakteapp uvm. Dadurch aktivierte die Geforce Experience das Mikrofon, um dem Streamenden die Aufnahme des selbst gesprochenen zu ermöglichen – Auch ohne Stream, was ich davon halte, gehört nicht hier her. Jabra erkennt das wiederum als Telefongespräch und schaltet in den Blechmodus…
Um dem entgegenzuwirken, können Sie die Einstellungen innerhalb der GeForce Experience aufrufen und unter „Allgemein“ den Schieberegler für „Spielinternes Overlay“ deaktivieren.
Ich habe leider keine Ahnung über die Tragweite des Problems, sprich ob andere Hersteller nebst Jabra so verfahren und ob andere – das Mikro verwendende Programme – ebenfalls diese Reaktion auslösen.
Viele Personen kennen diese Adressen gar nicht mehr, dabei basieren Termine und auch die gute alte Autovervollständigen-Funktion bei Eingabe einer Adresse in An:/Cc:/Bcc: noch immer auf diesen Adressen. In Folge dessen kommt es nach einer Migration oft zu Problemen bspw. beim reorganisieren von Terminen, so dass Teilnehmer nicht mehr benachrichtigt werden. Um dem entgegenzuwirken, kann man diese Adressen migrieren. Wie das geht, zeigen wir hier.
Export vom alten Domain Controller
Zunächst erstellen wir in der alten Umgebung mit Hilfe von PowerShell einen CSV-Export, der die Legacy-Adressen enthält.
Die CSV-Datei muss nun möglicherweise zu einem Server/PC kopiert werden, der auf die Exchange-Shell Zugriff hat. Dort angekommen importieren wir die Datei wieder und führen dann folgendes aus:
$Asdf = Import-CSV "C:\x500adresses.csv"
foreach ($User in $Asdf){ if ($User.legacyExchangeDN){ Get-Mailbox -Identity $User.UserPrincipalName | Set-Mailbox -EmailAddresses @{add="X500:$($User.legacyExchangeDN)"} } }
Ob die Migration erfolgreich war, kann über folgenden Befehl geprüft werden:
PowerShell-Script erfasst auf Host-Seite die nötigen Daten
Ansteuerung über Zabbix-Server mit Parametern (also kein Zabbix Trapper)
Verwendung aktueller Best-Practices – sprich am Besten ein „Raw Item“ aus dessen Inhalt die anderen Items berechnet werden, um den Datentransfer und die Kommunikation zw. Host und Zabbix-Server so klein wie nur irgendwie möglich zu halten.
Unser Szenario
Im konkreten Beispiel wird ein Script den Inhalt eines Ordners überwachen und uns alarmieren, wenn Inhalte im Ordner älter sind, als eine definierte Zeitspanne. Zusätzlich sollen gewisse Dateien innerhalb des Ordners ignoriert werden.
Schlussfolgerungen
Pfad, Zeitspanne und zu ignorierende Dateien werden als Macros ins Template übernommen und können somit auf Hostebene angepasst werden. Diese Macros werden dann in einem einzigen Item an den Host übergeben, der auf seiner Seite ein Script ausführt und die ganzen benötigten Informationen „raw“ zurückgibt. Wir erstellen dann weitere „berechnete Items“, die den Inhalt des „Raw Items“ auswerten und damit arbeiten.
Schritt 1: Das Script
Im Installationsverzeichnis von Zabbix (bei uns C:\ZABBIX) legen wir einen Ordner „userparameter“ an. Hier wird das Script „Get-OldFilesInFolder.ps1“ angelegt:
Entscheidend ist hier unsere letzte Zeile. Wir geben ein (zugegebenermaßen recht einfaches) Json-Objekt zurück. Unser „Raw Item“ wird somit nachher mit Json befüllt sein – der wohl sinnvollsten Möglichkeit in Zabbix mit multiplen Daten zu arbeiten.
Der zweite wichtige Punkt ist ganz oben im Script. Im „param()“-Block geben wir die Argumente an, die wir auf dem Zabbix-Host später übergeben müssen.
Schritt 2: Anpassung der zabbix_agentd.conf
Die wichtigste Zeile, die wir hinzufügen müssen, ist folgende:
Mit [*] geben wir an, dass das Item Parameter unterstützt.
Mit dem grün geschriebenen geben wir den Pfad zum Script an
Und die gelben Elemente sind die übergebenen Parameter, die auf keinen Fall weniger sein sollten, wie wir beim Item nachher übergeben.
Die zweite Zeile die angepasst werden muss, ist leider folgende:
UnsafeUserParameters=1
Da wir hier später einen Ordnerpfad übergeben, muss diese Option angepasst werden, da sonst die „Backslashes“ nicht akzeptiert werden.
Schritt 3: Erstellung des Templates
Um mit der etwas eigenwilligen Benennung von Templates seitens Zabbix compliant zu sein, habe ich das Template „Template Module Windows folder content by Zabbix agent“ genannt und in die Gruppe „Templates/Modules“ abgelegt. Mehr gehe ich auf das Design des Templates aber gar nicht ein – viel wichtiger sind andere Dinge:
Macros:
Hier erstellen wir nun die drei besagten Macros:
Macro
Inhalt
Beschreibung
{$FOLDERMONITORING.IGNORE}
Example,Template
Comma-separated list of ignored Files/Folders
{$FOLDERMONITORING.PATH}
C:\TEMP
Path to folder getting monitored
{$FOLDERMONITORING.THRESHOLD}
30
Threshold in seconds
Ist denke ich recht verständlich. Durch die einheitliche Benennung werden Sie später beim Host leichter zu finden sein.
Das Zabbix Raw Item
Nun kommen wir zur Erstellung des „Raw Items“ und somit zum Script-Trigger:
Name: Whatever floats your Boat
Type: Zabbix agent
Key: foldermonitoring.getstatus[„{$FOLDERMONITORING.PATH}“,“{$FOLDERMONITORING.IGNORE}“] Hier referenzieren wir die Macros. Auch andere Parameter können aber selbstverständlich angegeben werden.
Type of information: Text
Update interval: 1m (Zabbix Template Guideline)
History: 7d (Zabbix Template Guideline)
Applications: Zabbix raw items (Zabbix Template Guideline)
Description: Hier kann man beschreiben, was Hostseitig in der Config angepasst werden muss, damit das Item funktioniert
Enabled: klar.
Damit ist das „Raw Item“ schon fertig. Sollten Sie das Template nun an einen Host anbinden, auf dem das Script liegt und die Config entsprechend angepasst wurde, sollten Sie unter „Latest Data“ bereits Ihr Json-Objekt sehen.
Die berechneten Items (Dependent item)
Hier werden nun zwei Items erstellt – Bietet sich bei diesem Json-Objekt an:
Dependent Item #1 (Numeric)
Name: Whatever floats your boat
Type: Dependent item
Key: foldermonitoring.age
Master item: Auswahl des Raw-Items
Type of information: Numeric (unsigned)
Units: s (spezielle Unit für Zeitspannen)
History: 7d (Zabbix Template Guideline)
Trends: Do not keep trends
Show value: As is
Applications: File monitoring
Description: ¯\_(ツ)_/¯
Enabled: ja.
Das war jedoch noch nicht alles, wir wechseln stattdessen auf den „Preprocessing“-Reiter, um dem Raw-Item auch den richtigen Wert zu entziehen:
Add -> JSONPath -> $[„MaxAge“] Das ist die Json-Property, wie wir Sie im Script erstellten.
Add -> Custom multiplier -> 60 Hierdurch machen wir aus den Minuten Sekunden.
Dependent ITEM #2 (Text only)
Name: Whatever floats your boat
Type: Dependent item
Key: foldermonitoring.name
Master item: Auswahl des Raw-Items
Type of information: Text
History: 7d (Zabbix Template Guideline)
Applications: File monitoring
Description: ¯\_(ツ)_/¯
Enabled: ja.
Auch hier dann wieder auf den „Preprocessing“-Reiter wechseln und folgendes konfigurieren:
Add -> JSONPath -> $[„FileName“] Das ist die Json-Property, wie wir Sie im Script erstellten.
Schritt 4: Funktion prüfen
Falls nicht schon nach Erstellung des „Raw Items“ passiert, können Sie nun das Script auf einem Host ablegen, die Config des Agents entsprechend anpassen und in Zabbix dem Host das Template zuordnen. Wenig später (falls die Default-Werte eingehalten wurden, eine Minute später) sollten dann die Werte abgerufen werden und unter „Latest Data“ einsehbar sein. Die Macros müssen natürlich angepasst werden.
Schritt 5: Trigger erstellen
Nun können wir wieder auf das Template wechseln, um noch einen Trigger zu erstellen. Schließlich wollen wir ja melden, falls eine Datei tatsächlich älter ist als der im Macro hinterlegte Wert.
Auch hier werden wir wieder Best Practices anwenden – Somit kommen keine {ITEM.LASTVALUEX}-Attribute mehr in den Triggernamen, da diese seit Zabbix 4 (nicht komplett sicher) nicht mehr aktualisiert werden. Stattdessen kommen solche Infos in das Feld „Operational Data“. Gesagt, getan:
Name: File in ‚{$FOLDERMONITORING.PATH}‘ older than threshold ({$FOLDERMONITORING.THRESHOLD}m)
Operational Data: Age: {ITEM.LASTVALUE1} Immer klein halten, da es in Dashboards zusätzlich zum Triggernamen in der Zeile angezeigt wird
Serverity: Frei wählbar
Expression: {Template Module Windows folder content by Zabbix agent:foldermonitoring.age.last()}>{$FOLDERMONITORING.THRESHOLD} and {Template Module Windows folder content by Zabbix agent:foldermonitoring.name.strlen()}>0 Wir prüfen den Namen hier nur, um darauf zugreifen zu können
OK event generation: Expression
PROBLEM event generation mode: Single
OK event closes: All problems
Allow manual close: Nein.
URL: –
Description: Path of File: {ITEM.LASTVALUE2} Hier greifen wir nun den Namen ab um ihn anzuzeigen.
Enabled: Ja.
Abschluss
Das war es nun – wir haben unser Template erstellt. Was die Komplexität betrifft, war das natürlich gar nichts. Jedoch haben wir hierdurch einen guten Einblick in alle nennenswerten Mechaniken bekommen. Funktionstechnisch kratzen wir hier sicher nur an der Oberfläche.
Auf einem beliebigen Unix-OS folgenden Befehl ausführen:
openssl rand -hex 48
… um einen hexadezimalen PSK-Schlüssel mit einer Länge von 48 Zeichen zu erstellen. Hexadezimal muss er sein, das setzt ZABBIX voraus. Ob es bei der Zeichenlänge Limitierungen gibt, ist mir aktuell nicht bekannt. Diesen Key nun in die Zwischenablage kopieren.
Einspielen im ZABBIX-Server
In der Hostkonfiguration kann nun unter dem Reiter „Encryption“ folgende Einstellung gesetzt werden:
Connections to host:
PSK
Connections from host:
PSK
PSK-Identity
[z.B. der Hostname des Hosts]
PSK
[Key aus Zwischenablage]
Mit dem Speichern der Einstellungen wird die Verbindung zum Host unterbrochen, da der ZABBIX-Server nun eine verschlüsselte Verbindung voraussetzt.
Einspielen im Host
Auf dem jeweiligen Host muss nun die Config-Datei angepasst werden. Zuvor legen wir (am besten im Agent-Verzeichnis) ein Textfile ab, das den PSK-Key enthält. Diese nennen wir beispielsweise „psk.key“. Anschließend bearbeiten wir in der Agentconfig folgende Parameter:
# Pfad zur Key-Datei
TLSPSKFile=[Pfad zur Key-Datei]
# Wert für PSK-Identity
TLSPSKIdentity=[z. B. der Hostname]
# Akzeptierte Arten von eingehenden Verbindungen
TLSAccept=psk
# Art der ausgehenden Verbindung
TLSConnect=psk
Nachdem die Parameter entsprechend angepasst wurden, kann der Agent neugestartet werden. Sofern PSK-Identity und PSK-Key auf Server und Host übereinstimmen, sollte nun die Verbindung wieder erfolgen – verschlüsselt.
Bei der Ausführung und Weitergabe der Anleitung fanden wir jedoch heraus, dass man ein wenig Hintergrundwissen benötigt, um die Schritte umsetzen zu können.
Von einem an sich funktionierenden Zabbix-Agent wird hier ausgegangen.
Prüfen Sie über die Agent-Konfiguration, in welchem Ordner zusätzliche Configs eingelesen werden (Suchen nach „Include“-Parameter):
Include=/etc/zabbix/zabbix_agentd.d/*.conf
Erstellen Sie dort ein neues Config-File für mysql:
cd /etc/zabbix/zabbix_agentd.d/
nano userparameter_mysql.conf
… und fügen Sie folgenden Text ein …
#template_db_mysql.conf created by Zabbix for "Template DB MySQL" and Zabbix 4.2
#For OS Linux: You need create .my.cnf in zabbix-agent home directory (/var/lib/zabbix by default)
#For OS Windows: You need add PATH to mysql and mysqladmin and create my.cnf in %WINDIR%\my.cnf,C:\my.cnf,BASEDIR\my.cnf https://dev.mysql.com/doc/refman/5.7/en/option-files.html
#The file must have three strings:
#[client]
#user=zbx_monitor
#password=<password>
#
UserParameter=mysql.ping[*], mysqladmin -h"$1" -P"$2" ping
UserParameter=mysql.get_status_variables[*], mysql -h"$1" -P"$2" -sNX -e "show global status"
UserParameter=mysql.version[*], mysqladmin -s -h"$1" -P"$2" version
UserParameter=mysql.db.discovery[*], mysql -h"$1" -P"$2" -sN -e "show databases"
UserParameter=mysql.dbsize[*], mysql -h"$1" -P"$2" -sN -e "SELECT SUM(DATA_LENGTH + INDEX_LENGTH) FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='$3'"
UserParameter=mysql.replication.discovery[*], mysql -h"$1" -P"$2" -sNX -e "show slave status"
UserParameter=mysql.slave_status[*], mysql -h"$1" -P"$2" -sNX -e "show slave status"
Erstellen Sie in MySql einen Benutzer für Zabbix:
mysql -u <Root-User> -p
<Eingabe Passwort>
> CREATE USER 'zbx_monitor'@'%' IDENTIFIED BY '[Neues Passwort für den User]';
> GRANT USAGE,REPLICATION CLIENT,PROCESS,SHOW DATABASES,SHOW VIEW ON *.* TO 'zbx_monitor'@'%';
… jetzt haben Sie einen Benutzer ‚zbx_monitor‘ erstellt mit einem von Ihnen definierten Passwort (anstelle von [Neues Passwort für den User])
Nun kommt der Punkt, der von ZABBIX nicht erklärt wird: Die Verbindungsdaten müssen nun im Home-Laufwerk des Zabbix-Benutzers abgelegt werden. Das hat er jedoch standardmäßig nicht. Wir legen nun also dem Benutzer ein Home-Laufwerk an:
# Ordner anlegen
mkdir -p /var/lib/zabbix
# Berechtigung setzen
chown zabbix:zabbix /var/lib/zabbix
# Zabbix Agent stoppen (sonst gehts nicht)
service zabbix-agent stop
# Dem Zabbix-Benutzer das Homelaufwerk zuordnen
usermod -d /var/lib/zabbix zabbix
# Jetzt kann der Agent wieder gestartet werden
service zabbix-agent start
Jetzt kann die Verbindungsdatei hinterlegt werden:
nano /var/lib/zabbix/.my.cnf
[client]
user=zbx_monitor
password=[Neues Passwort für den User]
… das sollte es gewesen sein. Am Besten abschließend den Zabbix-Agent nochmal neustarten: